To kick off the open fun for this year, we will start off with a short discussion on open project management. Although people should think of this in a tool-free manner, we will address broad principles using
Slack and
Open Science Framework (OSF).
Slack as a laboratory group tool: I began using Slack several years ago when the
OpenWorm Foundation started using it to facilitate shared communication and manage new members. Since then, it has become increasingly popular as a laboratory personnel and collaborative management tool [1]. I started the Orthogonal Lab Slack about a year ago, and it has been useful for disseminating intragroup messages, news, media, and short presentations. This is especially good for academic collaborations, particularly when the group members are not co-located [2].
Once your group has a Slack space (with a URL such as your-group.slack.com), you must a) create channels, and b) recruit members. Whether your group is large or small, Slack seems to scale well in most cases. Each channel is thematic, and allows for parallel communication between channel members. Media (files, images, links) can be shared with ease, and private messages are also possible. Additional functionality is possible through the use of bots (e.g. time-management tools such as
todobot or
slackodoro). In many ways, Slack is an alternative to the e-mail chain. However, integration with other platforms (such as
Twitter or
Skype) is also possible.
An infographic on Slack productivity in the academic workplace, courtesy of
Paperpile.
COURTESY: Using OSF at the University of Notre Dame.
YouTube.
Open Science Framework (OSF) as project pipeline and showcase: I have been using OSF for storing work at the project level for exposition to potential funders and other interested parties. More generally, OSF is used to promulgate both the progression and replicability of research projects [3]. From a technical perspective, OSF also features version control (using
Git), doi creation, and storage space for papers, presentations, and data. OSF also offers
an API and an
open dataset on research activities. OSF also has a portal called
Thesis Commons for theses and dissertations. You can also store datasets,
digital notebooks, and link to
Github-hosted code using the OSF project structure.
Potential destinations for objects of the OSF workflow. COURTESY: Ref [4].
The OSF offers a means to manage all scales of research output.
Artem Kaznatcheev has provided an
informal taxonomy of research output types as well as their scale of importance. According to this view, examples of the these scales include the following: standard (blog), kilo (conference pubs), giga (journal pubs), and tera (book/thesis) scales. Although arbitrary in terms of content, these scales might more closely define
the number of hours invested in creating a particular type of research document. OSF projects can include combinations of research output types to provide a richer window into the research process.
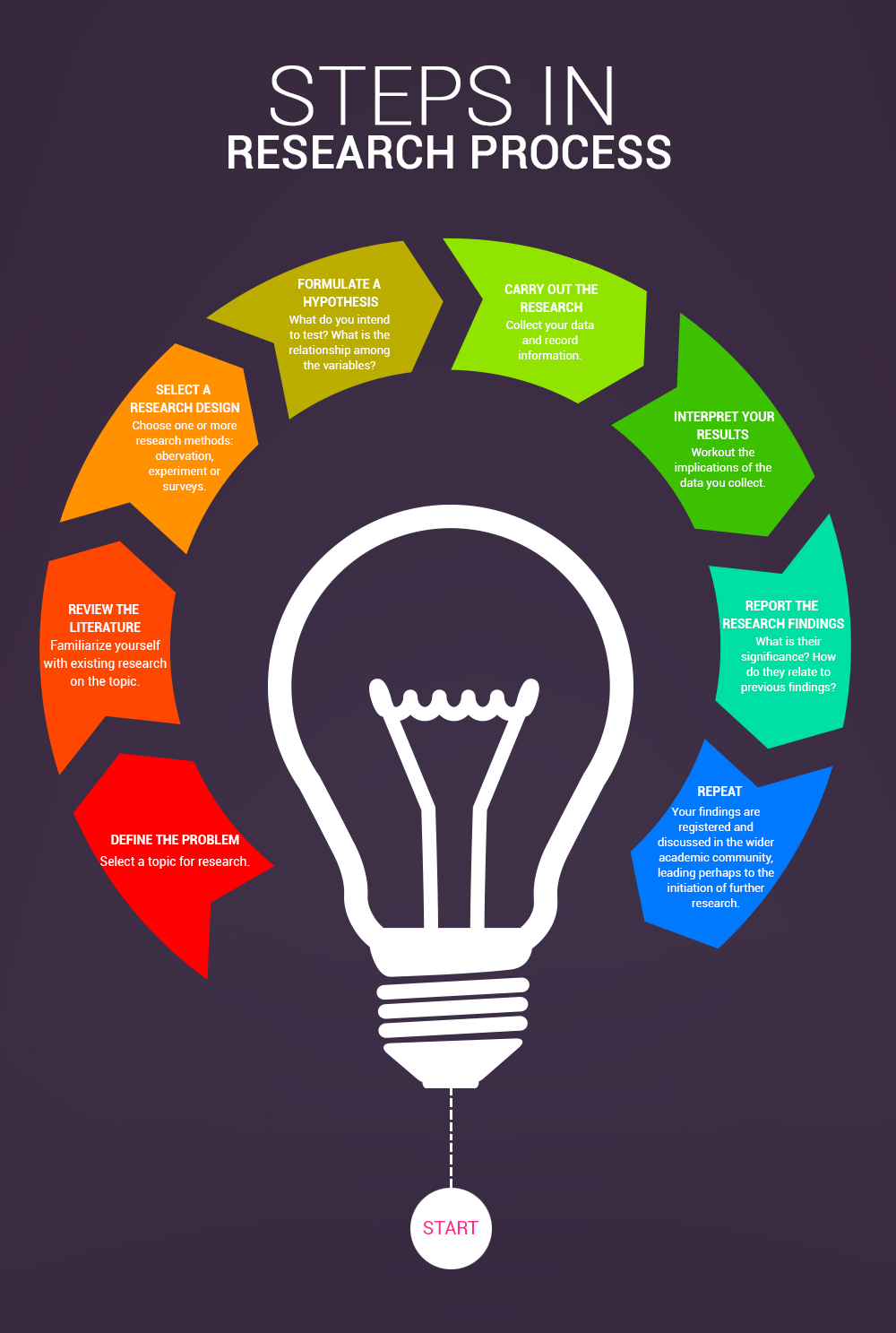
Steps in the developing research (or, how to get to research outputs).
COURTESY: Visual.ly
[1] Some examples include:
a)
Slack inside the MacArthur Lab. SlackHQ blog, April 27 (2015).
b) Washietl, S. (2016).
Six ways to streamline communication in your research group using Slack. Paperpile blog, April 12.
c) Perkel, J.M. (2016).
How Scientists Use Slack. Nature News, 541, 123. Managing organizational to-do lists in Slack.
[2] OpenWorm Slack has a bi-weeky event called Office Hours where people meet and have topical conversations.
Join us via Slack Pass if you are interested.
[3] Foster, E. and Deardorff, A. (2017).
Open Science Framework (OSF). Journal of the Medical Library Association: JMLA, 105(2), 203-206.
[4] Anonymous (2016).
Response from COS. Medium, April 2.