
I: Biological Variation: an epistomological tour
This month was a provocative one for those interested in human biological variation. Nicholas Wade's book "A Troublesome Inheritance: genes, race, and human history" is being roundly criticized by Anthropologists [1] and Evolutionary Biologists [2] alike. While I have not read the book, I have gleaned the basic outline from various reviews and recaps. But from what I understand about it, the book is based on the notion that the study of human biological variation has not been treated fairly in the history of science. That is to say, people who are satisfied with the phrases "there are no such thing as race" or "races are sociopolitical entities" [3] are ignoring up-and-coming work in the area of human genetics. And indeed, recent findings based on technologies such as genome resequencing and functional genomics might suggest a interpretive revision is necessary.
As Wade would have it, this research suggests that human subdivision is a real phenomenon, much like species or other biological classifications. This in and of itself would be an incomplete argument. But the way in which Wade links human genetic diversity to behavioral differences and confounds racial categories with cultural groups is a source of great controversy. In fact, a book review by Andrew Gelman [4] highlights both the preposterous and plausible nature of Wade's argument. The preposterousness of Wade's argument lies in its extramission theory-like reliance on genes enabling behavioral tendencies based on cultural identity. The plausibility lies in the recognition of population sub- structure, which will be discussed later in this post.

Spatial distribution of a single human phenotypic trait (skin color). Is there any significance to these geographic patterns, and how can we tell? Some people think a map like this contains self-evident truths, others do not.
My impression of Wade's argument boils down to this: the argument against human population subdivision (racial classification) is largely driven by political correctness, and all we need to do is apply the right science to see the truth. There is a circularity and self- evident quality to this argument that is somewhat disturbing. Unfortunately for Wade, he uses precious little insight from either Population Genetics nor modern Evolutionary Anthropology. So the Evolutionary Anthropology/Biology critique is not merely based on enforcing conformity, it is substantive and necessary. And as we will later see, the interpretation of human biological variation is much more complicated than many people will admit to.
I would be remiss to say that Wade is not without his supporters [5]. A more cynical eye might label him (Wade) and these supporters as "scientific racists" or "deniers" (the denier label has also been applied to Anthropologists by a likely Wade supporter). But the real problem is the dialogue between different scientific research group and fields of study. In the study of variation and its consequences, what is obvious to a person in one field might take someone in another field completely by surprise. People who are unfamiliar with nuanced variation-dependent thinking are more likely to embrace the notion that there is something fishy about these ways to deal with variation and instead choose a so-called common sense approach. But because science is so (unnecessarily) hyper-specialized, perhaps we should not expect an full accounting of variation from any one group or field. Instead perhaps we should play the long game of interpreting variation.
II. How do we approach human structural variation?
The debate between Agustin Fuentes and Nicholas Wade [6] operationalizes this gap in understanding in two ways. First, Wade sets up a straw man in declaring that the standard Anthropological view only considers races as socio-political categories rather than biological ones. But since biological differences between human populations are self-evident (albeit at a superficial level) and consistent with so-called common sense, this view must be erroneous (or at least severely flawed). Yet this is a conceptual assumption on Wade's part -- racial categories are often based on superficial biological attributes, but rooted in social context and the fluid nature of identity over time. This is the essence of the Anthropological lesson: biological features and social context often cannot be disentangled. Secondly, Wade uses an example of several geographically- distinct "natural" groups being generated by a program called Structure [7]. One might think that a statistical argument would supercede any conceptual arguments that might be rooted in ideology. But as I will show you, so-called racial categories cannot be easily statistically disentangled from other structural features of human populations, either.

This is what a cluster analysis with structure looks like (a generic example). Considering that this is an unsupervised form of machine learning and a rather exploratory form of data analysis, should this be the standard tool for the analysis of human genomic variation? COURTESY: R and Bioconductor manual.
So is Wade's argument typical of contemporary thinking on human biological variation? We can look to research groups located at Stanford (Pritchard Lab), Chicago (Lahn Lab) [8], and UC Santa Cruz (Haussler Lab) for instructive lessons. These groups have found both structured variation and intriguing differences between populations, but unlike Wade do not associate it with broad cultural characterizations. Their hypothesis is that natural selection has acted extensively on modern human populations, owing largely to regional environmental adaptation [9]. This has included adaptations for lactose tolerance and the discovery of human accelerated regions (HARs) [10]. Indeed, there is accumulating evidence that evolutionary adaptation has occurred on a regional basis in modern humans even within the last 10,000 years (e.g. fast evolutionary change). This has resulted in regional distinctions between populations [11], but whether these demographic changes warrant formal taxonomic distinction is another matter.

A standard PCA analysis shows that genotype can predict geographic origin of genotype. COURTESY: Gene expression blog.
Indeed, while these differences may serve to support the existence of biological races [12], it is unclear how these are precisely defined. Should it be based on the geographic distribution of variation [13], or should it be based on genealogical continuity? So even when we are not dealing with the naive theories of Wade, traditional taxonomic views of race are still problematic when dealing with the complexity of intraspecific variation. What kinds of lessons can we learn from all of this? I will now propose several points that suggest how we might address human variation in an informed manner that incorporates multiple points of view.

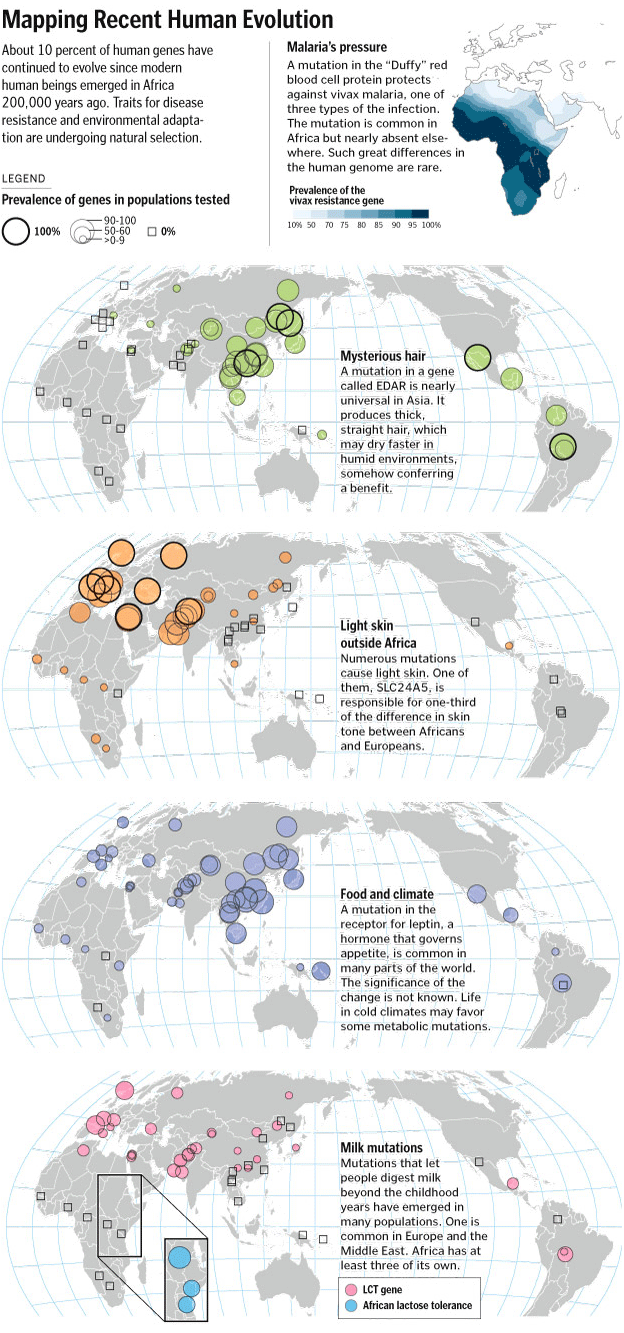
Map showing selected examples of recent human evolution. COURTESY: Washington Post.
1. Geography does not equal natural subdivision.
In all of the reviews of Wade's book, it has never been mentioned why cluster analyses might not be the best way to uncover the true structure of intraspecific variation. So why is it incorrect to look for "natural subdivisions" using a cluster analysis? Because what Wade and others claim to be "natural" subdivisions of genetic diversity may actually be geographic artifacts.
In the Fuentes/Wade debate and in a blog post by Jennifer Raff [14], it is mentioned that a series of experiments can be conducted using k-means cluster analysis. The Structure program provides a k-means-like cluster analysis (or perhaps more accurately, a k-class cluster analysis) with corrections for the effects of admixture between groups [15]. k-means cluster analysis is, of course, a method for specifying the structure of a dataset a priori. In this type of supervised cluster analysis, the number of categories (of order k) should correspond to the number of actual sub-categories (or structure) in the data. Quite telling is that when the value for k is set above 5, the analysis produces clusters which are not geographically mixed (e.g. European and Asian populations in the same group).
One way to correct for this bias is to perform a spatial decorrelation (e.g. spatial PCA) [16]. This would result in removing the similarity of individuals due to shared location [17]. This may seem counterintuitive at first, but consider why this might be important. While a race might be defined by singular traits (e.g. eye color or skin color), these are not robust enough to constitute meaningful population structure in and of themselves. If biological subdivisions do indeed exist, then we would want a classificatory scheme that includes as many traits (e.g. dimensions) as possible without picking up the consequences of traits being co-located in space.
2. Allele frequencies are not dynamic information in and of themselves
Another issue is that even though population structure exists among Homo sapiens, contemporary data are merely a static snapshot of our species. And in a cultural species such as Homo sapiens, the extensive populations bottlenecks that define migration events and ethnogenesis play a large role in defining structure. These structural features have the potential to mimic more systematic gene flow restriction and racial group-specific evolution. Any hypothesis of systematic population structure in humans must also consider alternative explanations such as these.
An Analysis of Molecular Variance (AMOVA) [18] should generally reveal that there is more variation within than between many continental level subdivisions of Homo sapiens. Thus, there is no reason to believe that races (if they exist) have to be geographically distinct any more than continental groups being homogeneous. But perhaps they do not exist, and do not serve as a stable and reliable taxonomic category. A paper by Long and Kittles [19] considers four different race concepts based on patterns of the genetic fixation parameter Fst: typological, population, taxonomic, and lineage. While the measurement of allele frequencies reveal more variation than expected using Fst, these data are still not consistent with formal taxonomic (e.g. racial) subdivisions.
3. Environment is both the problem and the solution
A third issue involves the role of GxE, or the interaction of genes and environment. While there are of course formal GxE tests in modern genetics, my purpose here is to point out what is perhaps the true role of environmental influences on variation. To understand this, we must return to the standard Anthropological position on race. Paraphrased, this position states that in the scheme of history races are sociopolitical entities, the biological significance of which are diluted by the nature of identity. So as we can see, environment actually involves explicitly cultural adaptation with its own structural features. This may give rise to an additional term: GxExC.
This cultural variance, unlike the environmental variance found in other mammals such as foxes or hedgehogs, can be substantial. But does culture act as a multiplier of genetic effects, or as a buffer from genetic effects? It really does depend on both the social and biological context. On the one hand, culture has allowed populations to adapt to new environments without the need for genomic adaptation. On the other hand, environmentally-driven genomic adaptations have allowed for cultural innovation. It may be best to consider this relationship between culture and genome as a dual-process model, the evolution of which can often be independent of any nominal genetic structure.
4. Variation is not straightforward
Finally, there is a question of how you compare groups of equal amounts of variation and keep behavioral influences on migration and other factors [20] to a minimum. If you are looking to not compare apples and oranges [21], one must keep this issue in mind. What type of group is a valid subdivision, particularly for comparative purposes? Is the fundamental level of subdivision continental, or based on ethnic group, or is it simply one of restricted gene flow? Due to their basis in migration and identity, human ethnic groups can be either contrived (e.g. of a polyglot nature) [18] or homogeneous. Even in cases where significant structure exists, the link to broader social relevance (e.g. cultural diversity and traits) is questionable at best [22].
What is the true structure of our species and how does it matter for purposes of classification? One is that even though some interbreeding has been found to occur between modern humans and archaic species, the trend of recent human expansion out of Africa (the RAO model) is still predominant [23]. This suggests that the apparent structure in human genetic data may not be all that deep, pointing towards strong contributions from so-called fast evolution. While fast evolution may be sufficient to drive racial population structure on its own, the nature of changing political boundaries and population patterns make traditional biological classification somewhat superfluous for humans [24].

The tempo and broad overview of human demographic expansion, according to the RAO model.
5. Population genetics + Linnean taxonomy might not be the answer
There are also several problems with the concept of race as a taxonomic (a) and organizational (b) term. Let's look at each of these in more detail.
a) Linnean-style classification below the species level is problematic. As putative sub-categories of a species, races are not defined in the same way as a species. Aside from there being many species definitions, the most popular (the Biological species concept) is based on molecular mechanisms for reproductive isolation and the genesis of dinscontinuous variation. This is true even among populations that evolve in a spatially comingled fashion. However, defining races (and their emergence) using a systematic approach is much trickier, and would presumably involve restricted gene flow within humans. But despite geographic barriers and the local concentration of certain adaptations and traits [25], the assumption that intraspecific structure should necessarily be nested or discrete is likely misguided [24].
b) To assess significant population structure, we often begin from a condition of panmixia. Panmixia is a situation where every member of the species (or population) have an equal chance of breeding with one another. This is often thought of as random assortment, and so restrictions in gene flow will lead to a signature of population subdivision (groups which are called demes). However, consider that
The problem is that we typically use panmixia as the null hypothesis. A more plausible (to me) null model is something like a scale-free or even small-world network, complete with highly-connected populations and weak connectors between populations. This would not only account for all possible configurations of interbreeding relationships (which are heavily influenced by culture) over evolutionary time, but also would account for the dual inheritance and evolutionary processes of culture and biology simultaneously [26].

A scenario for modern human demographic expansion. Notice the role of migrations and population expansions. COURTESY: Figure 1 in [27].
So what does the long game of human biological variation involve? It helps to resist the temptation of approaching the issue from a solely reductionist perspective. While large-scale genetic data give us a formidable advantage in the understanding of human diversity [28], not making the link to social complexity and phenotype makes the technology and the science involved much less useful. But sometimes one source of data can help drive the entire enterprise forward. In Pritchard, Pickrell, and Coop [29], whole-genome data allows them to propose a new mechanism called polygenic adaptation, which allows for rapid adaptation in a population without the need for selective sweeps. While this stands at odds with comparative morphology, physiology, and conventional population genetics, and thus might be incorrect, it also might help us make sense of the big question in a new light. New analytical tools and a unification of theoretical perspectives can also help, particularly in an area where the potential for mythology and biases are rife. Given that "nothing in the study of variation makes sense with complexity" [30], a vision that transcends discipline and investigative approach is absolutely required.
NOTES:
[1] Anthropologists chime in: Fuentes, A. The Troublesome Ignorance of Nicholas Wade. HuffPo blog, May 19 (2014) AND Marks, J. The Genes Made Us Do It: the new pseudoscience of racial difference. In These Times, May 12 (2014) AND Dunsworth, H. If scientists were to make the arbitrary decision that biological race is real, can you think of a positive outcome? Mermaid's Tale blog, May 22 (2014).
[3] Although this paper serves as a means to make sense of human variation from an Anthropological perspective that goes beyond sloganeering: Weiss, K.M. and Fullerton, S.M. Racing around, getting nowhere. Evolutionary Anthropology, 14, 165-169 (2005).
[4] Gelman, A. The Paradox of Racism. Slate Magazine, May 8 (2014).
[5] One take on the relative merits and of Wade's book and support of his argument can be found here: VanBruggen, R. Race is Real. what Does the Mean for Society? RealClearScience blog, May 6 (2014).
[6] Rex What Happened at the Fuentes-Wade Webinar. Savage Minds blog, May 14 (2014).
[7] Wade, Nicholas. Gene Study Identifies 5 Main Human Populations, Linking Them to Geography. NY Times, December 20 (2002). But also see this article as a follow-up: Rotimi, C.N. Are medical and nonmedical uses of large-scale genomic markers conflating genetics and 'race'? Nature Genetics, 36(11), S43-S47 (2004).
[8] For more information, please see the following citations:
a) Raj, A., Stephens, M., Pritchard, J.K. Variational Inference of Populations Structure in Large SNP Datasets. Genetics, doi:10.1534/genetics.114.164350 (2014).
b) Atkins, C.E. Bruce Lahn Interview. H+ Magazine, May 12 (2012).
c) Seed Interview: Bruce Lahn. Seed Magazine, September 11 (2006).
[9] McAuliffe, Kathleen. They Don't Make Homo Sapiens Like They Used To: Our species—and individual races—have recently made big evolutionary changes to adjust to new pressures. Discover Magazine, Feb. 2, 2009.
[10] Pollard, K.S., Salama, S.R., King, B., Kern, A.D., Dreszer, T., Katzman, S., Siepel, A., Pedersen, J.S., Bejerano, G., Baertsch, R., Rosenbloom, K.R., Kent, J., and Haussler, D. Forces shaping the fastest evolving regions in the human genome. PLoS Genetics, 2(10), e168 (2006).
[11] Hsu, Steve. Demography and fast evolution. Information Processing, Aug. 9, 2011.
[12] More biologists chime in: Moran, L.A. Do Human Races Exist? Sandwalk blog, March 1 (2012) AND Lahn, B.T. and Ebenstein, L. (2009) Let's celebrate human genetic diversity. Nature, 461, 726-728.
[13] For the integration of genealogy and geography, please see: Tishkoff, S.A. and Kidd, K.K. Implications of biogeography of human populations for 'race' and medicine. Nature Genetics, 36(11), S21 - S27 (2004).
Please also see the following reference: The Genographic Project. National Geographic.
[14] Another Anthropologist chimes in: Raff, J. Nicholas Wade and race: building a scientific facade. Violent Metaphors blog, May 21 (2014).
[15] UPDATED 7/15/2014: If you are wondering as to the technical details of the clustering approach used in Structure, see the following blog post: Pontikos, D. k-means and Structure. Dienekes' Anthropology Blog, July 15 (2014).
Technically, Structure does not actually use k-means. Instead of using k-unimodal centroids (or assuming normally-distributed categories), the algorithm underlying Structure uses bimodally-determined classes to account for the existence of potential admixture. Again, this is done to correct for artifact due to admixture and other sources of genealogical recombination. However, the issue of potential spatial artifact remains.
a) Spatial PCA: Novembre, J. and Stephens, M. Interpreting principal component analyses of spatial population genetic variation. Nature Genetics, 40(5), 646-649 (2008).
b) General Classification: Hariharan, B., Malik, J., and Ramanan, D. Discriminative Decorrelation for Clustering and Classification. Lecture Notes in Computer Science (LNCS), 7575, 459-472 (2012).
[17] Epperson, B.K. Geographical Genetics. Princeton University Press (2003).
[18] The AMOVA is a relative of the ANOVA (Analysis of Variance). For more information, please see: Excoffier, L., Smouse, P., and Quattro, J. Analysis of molecular variance inferred from metric distances among DNA haplotypes: Application to human mitochondrial DNA restriction data. Genetics, 131, 479-491 (1992).
[19] Long, J.C. and Kittles, R.A. Human Genetic Diversity and the Nonexistence of Biological Races. Human Biology, 81(5-6), 777-798 (2009).
[20] Foster, S.A. The Geography of Behavior: an evolutionary perspective. Trends in Ecology and Evolution, 14(5), 190-195 (1999).
[21] Frost, P. Apples, Oranges, and Genes. Evo and Proud blog, November 5 (2011).
[22] Khan, R. Human Races May Have Biological Meaning, But Races Mean Nothing About Humanity. Discover's The Crux blog, May 2 (2012). Please also see the November 2004 supplemental issue of Nature Genetics on human variation for many enlightening articles.

[24] Laden, G. The Scientific, Political, Social, and Pedagogical Context for the Claim that "Race does not exist". Greg Laden's blog, November 29 (2008).
[25] Novembre, J., Galvani, A.P., and Slatkin, M. The Geographic Spread of the CCR5 Δ32 HIV-Resistance Allele. PLoS Biology, 3(11), e339 (2005).
[26] Richerson, P.J. and Boyd, R. Not By Genes Alone: How Culture Transformed Human Evolution. University of Chicago Press (2005).
[27] Balaresque, P.L. Challenges in human genetic diversity: demographic history and adaptation. Human Molecular Genetics, 16(R2), R134-R139 (2007).
[28] Tennessen, J.A., O'Connor, T.D., Bamshad, M.J., and Akey, J.M. The Promise and Limitations of Population Exomics for Human Evolution Studies. Genome Biology, 12, 127 (2011).
[29] Pritchard, J.K., Pickrell, J.K., and Coop, G. The Genetics of Human Adaptation: hard sweeps, soft sweeps, and polygenic adaptation. Current Biology, 20(4), R208-R215 (2010).
[30] a play on the classic Dobzhansky quote. Dobzhansky's views on the race concept evolved over time from seeing races as biological "clusters" fixed in space to races as "Mendelian populations" . For more, please see: Gannett, L. Theodosius Dobzhansky and the Genetic Race Concept. Studies in History and Philosophy of Biological and Biomedical Sciences, 44(3), 250-261 (2013).





































{kind=link}